Nov 03, 2021
While planning drag and drop image support in Chronicles, I had some confusion about handling files once dropped. There are many tutorials out there but they often provide a “copy this code” approach and offer little insight. Many recommended using base64 encoding but that did not seem right. The more general problem of file uploading through a browser is one I occassionally return to, so I wanted a conceptual deep dive I could use as a foundation. After reviewing and taking notes, I organized some of them into this blog post here.
This section briefly touches on the design goals that motivated this research. I also review two implementations (Notion, Github) as a basis for the feature. Feel free to skip ahead.
I reviewed a few existing apps to get a feel for their implementation, and broke what I saw down to this:
Because I think they are good examples, I include here how Github and Notions drag and drop work.
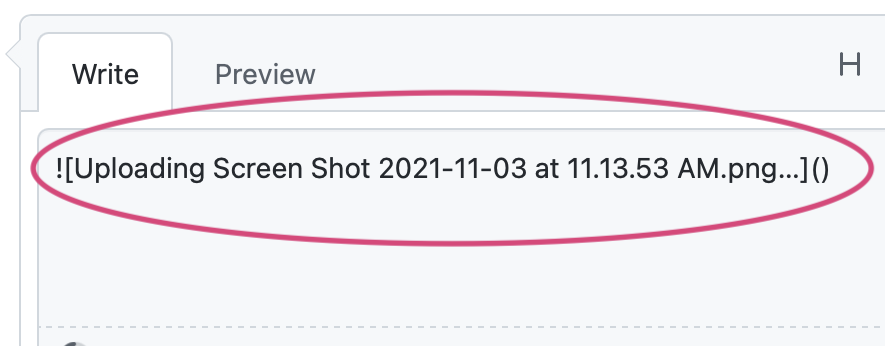
Github’s image upload is minimal. When you drop an image onto their plain <textarea>, it begins the upload while adding a placeholder indicator:
The file upload happens via a POST request using multipart/form-data encoding.

Once the upload is complete, it replaces the placeholder with an img tag pointing to the url. The file url itself is a randomly generated ID (looks like a uuid) in place of the original filename and points to Github’s CDN. There’s no inline rendering of the image during or after upload, unless you click the preview tab.

Notion’s is a bit fancier. It renders the image while it uploads, providing a status bar in the bottom right:

It appears to send it as a PUT request and get back a URL pointing to s3, which then replaces the image above.

The full process is a bit more involved but beyond the scope of this document. There’s some dynamic checking for which server to upload to, and it appears to do things differently if you drop multiple images. Digging in further could interesting for a future post.
After reflecting on the implementation, I think there are four components to implementing basic drag and drop images:
Where the backend is concerned, the few examples will use NodeJS.
To start its helpful to understand how an HTML form lets users add image files and how we can interact with them. Consider this form with a file input:
<form enctype="multipart/form-data" method="post">
<input id="files-input" type="file" multiple accepts="image/*" />
<button type="submit">Upload</button>
</form>
On its own, a user can interact with this form to send files to the server without any javascript. The enctype is important and will be discussed when we look at sending to the server. The file input offers an API accessible via javascript, and this can be used to inspect files added by the user as well as to dynamically add files to the form:
const filesInput = document.querySelector('#files-input');
for (const file of [...filesInput.files]) {
console.log(file.name, file.type, file.size)
}
The files object is a FileList. It can be iterated using spread syntax, Array.from, or manually (using files.length) but is not an array itself. Each File object has properties for checking its name and type (extension) but not its path. Contents may be read via various API calls but are not loaded automatically; more on this later.
The “Drag and drop” APIs at a simplistic level give you a way to access a FileList from a user dropping files onto a designated area. You have to register event handlers on a container element, stop the default behavior, then do something with the FileList. The simplest thing is attach them to the form defined in the previous section:
// Any area of the page you'd want users to drop files
const dropArea = document.querySelector('#files-drop-area')
const filesInput = document.querySelector('#files-input');
// dragover and dragenter default behaviors must be cancelled for
// drop to work
dropArea.ondragover = dropArea.ondragenter = (event) => {
event.preventDefault();
};
// handle dropped file(s)
dropArea.onDrop = (event) => {
event.preventDefault();
// this attaches the dropped files onto the HTML form setup previously
fileInput.files = event.dataTransfer.files;
form.submit()
}
In a nutshell, that is how most image upload forms work and why the preceding section was relevant: Add a normal form, then enhance it with drag and drop.
To send the file to a server, you don’t need to read its contents — there are a few ways to stream the contents directly. However many tutorials detour into reading file contents, often as base64. I found it helpful to understand why you might do this.
First, having a File object we can use a FileReader to read its contents. There are multiple ways depending on your needs — as binary data (ArrayBuffer), a data url, or text (w/ encoding specified). The readAsDataUrl method encodes the image in base64, then embeds it as a data url. Many tutorials would utilize this to display an image preview:
const img = document.createElement("img");
someContainer.appendChild(img);
const reader = new FileReader();
reader.onload = (e) => {
img.src = e.target.result;
}
// read a file obtained from a FileList
reader.readAsDataURL(file);
Base64 was once popular for inlining images for performance reasons, although it seems that should be done in only specific cases. There are some storage and transmission use cases for base64 but for basic uploading and saving a file to disk, it is not required.
But should “I need an image preview” be synonymous with base64 encoding? Apparently not. Instead of reading and encoding the image as a base64 string, you can use Object URLs:
// Rather than using a FileReader, the src can be set to the
// ObjectUrl's return value
img.src = URL.createObjectURL(this.files[i]);
// confusingly, you must clean up the reference after its been loaded
// (or after you are done using it in your SPA)
img.onload = function() {
URL.revokeObjectURL(this.src);
}
Object URL’s are a bit mysterious to me, and something I’d like to dive deeper on in the future. For now my take aways are that they provide a way of avoiding the overhead of base64 encoding when dealing with File contents. I.e. you could use the object url for display purposes then rely on the original File object to upload it, if relevant. If I dealt with a lot of images or an image focused app I might spend some time playing with these API’s a bit further.
Once you have a handle on the file, you’re ready to send it to the server; there are a few options:
FormData APIenctypeThe example above used an HTML form to send the file to the server, but there’s an important bit about the “enctype”. An HTML form without files is, by default, handled a bit differently than one with files. The content-type at submit is set to application/x-www-form-urlencoded. Sending images this way will not work unless they are encoded as text (i.e. base64) but, as mentioned previously, you don’t need to do that. Instead you can send the form as “multipart”, which is an alternative method (see HTML 4 spec here) where the browser can send a request with multiple “types” of data. You can opt into this behavior by adding the enctype="multiepart/form-data" attribute to the form. With this in place, the browser will stream the files binary contents within the form submission request. As long as the server is setup to handle such a request (see below), the front-end component is complete.
FormData APIThe FormData API allows for dynamically constructing a set of form fields in javascript. This API shows up commonly in drag and drop tutorials because it lets you skip setting up or using an existing HTML form.
// handle dropped file(s)
dropArea.onDrop = (event) => {
event.preventDefault();
const formData = new FormData()
const files = event.dataTransfer.files;
// this attaches the dropped files onto the HTML form setup previously
for (let i=0; i<files.length; i++)
formData.append(`file_${i}`, files[i], files[i].name);
}
// sends as multipart/form-data
fetch('https://mybackend.dev/fileupload', {
body: formData,
method: 'POST',
}
}
For many kinds of SPA’s (like a notes app) it may be awkward to stuff an invisible and otherwise unused HTML form into the page; this API lets you skip that step.
The above two examples are what you’ll most commonly find in tutorials. But there’s also an extremely simple third way to do this, which incidentally is what sent me down this rabbit hole in the first place. You can send File objects directly with fetch:
// after getting files from ondrop event
for (const file of [...event.dataTransfer.files]) {
fetch('https://mybackend.dev/uploadfile', {
method: 'POST',
body: file,
});
}
The browser will infer the mime type and pass that as a header. If your use case is sufficiently constrained (ex: don’t care much about file size; dynamically generating names on server) this might be suitable. Its definitely great for prototypes and in my use case, this is how I did it. This is also quite simple to “handle” on the server; more on that below.
When thinking about multi-part having disparate sections, it reminds me a lot of the JSON protocol. Moreover 99.9% of the time I’m using fetch, I’m sending JSON. My mind naturally wondered about it here — can I pass some additional data in a JSON object, and simply include the file as one of the fields? Well yes, but there’s an important caveat: JSON doesn’t support binary data. This would require base64 encoding the data with the associated shortcomings. It may be something you need to do, but if all you want is some metadata with the file(s), you are better off sending as multipart/form-data or even with custom headers in a fetch request.
Driving this point home, here’s a great stackoverflow question on the subject: Binary Data in JSON String. Something better than Base64. Note how the multipart response (not the accepted answer) is somewhat revelatory to some readers. Its natural to have JSON blinders on when 99% of the data you pass around is in that format, that’s the interchange default on the front-end. Yet for binary data there are at least two better options: Fetch and multipart/form-data. Both will let you stream data without first encoding in a different format.
How you handle the request on the backend depends on how you sent it. For this example I’ll use Node as an example, since that’s the server I had already setup.
To keep it simple, all we’ll ask the backend do is the following:
The most important concept to understand what needs to happen, is to understand how the file was encoded into the request. Specifically, if the file is embedded within JSON or a form, the request needs parsed.
fetch and FileWhen sending the File as the body of fetch directly, the body does not need parsed at all, because it was not encoded into base64 nor embedded into a particular protocol — it was sent as is. Thus processing the file can directly write the contents to disk:
// Stream a requests contents to a file
//
async function save(req: IncomingMessage, filePath: string) {
// Take in the request & filepath, stream the file to the filePath
return new Promise((resolve, reject) => {
const stream = fs.createWriteStream(filePath);
// Not actually sure if I need to setup the open listener
stream.on("open", () => {
req.pipe(stream);
});
stream.on("close", () => {
resolve(filePath);
});
// If something goes wrong, reject the primise
stream.on("error", (err) => {
reject(err);
});
});
}
// upload a file
// note error and validation handling omitted for brevity
async function upload(ctx: RouterContext) {
// use provided extension, but randomly generated name
const extension = mime.getExtension(ctx.request.headers["content-type"]);
const filename = `${cuid()}.${extension}`;
const filepath = path.join(this.assetsPath, filename);
await Files.save(ctx.req, filepath);
ctx.response.status = 200;
ctx.response.body = {
filename,
filepath,
};
};
This code takes advantage of the browser automatically setting the mime type and uses a mime-to-extension library — both good reads to get a handle on dealing with validation and errors (omitted for brevity; see also here). I chose cuid for generating filenames and other than the validation and file naming aspects, there’s no special handling of the request required. Streaming to a file and returning a url to it is all that is required to have a functioning file upload.
If the file comes in from a multipart/form-data upload, you’ll need to parse the request before using the files. In Node, typical request parsing libraries may or may not include multipart form parsing out of the box. As an example, the koa-body library for koa does and might look like this:
const Koa = require('koa');
const koaBody = require('koa-body');
const app = new Koa();
app.use(koaBody({ multipart: true }));
app.use(ctx => {
for (const file of ctx.request.files) {
console.log('file metadata', file);
}
// ...
});
Peeling back the layers, the koa-body library delegates multipart form parsing to formidable; the file objects are metadata and the underlying file data are written to disk by default. This might be surprising behavior — in general I found that dealing with multipart forms is somewhat involved. You need to figure out what you want to do with the file(s) as you parse them, whether you want them stored as intermediate files or streamed to s3 for instance. Most express and koa middleware libraries are based on one of two underlying Node libraries:
Were I to build a production worthy file upload service, I’d likely invest my time in researching those two options, and selecting the one that fits my use case best. Working up towards a higher level framework wrapper (like koa-body) would be well informed by said research. Using either directly would also be perfectly suitable.
I hope the above review of drag and drop file uploading was helpful. After building an understanding of multipart forms and using File references, I found I was able to more easily evaluate various blog posts, form libraries, and questions related to them. I was a bit surprised at the amount of misinformation out there and I suppose the topic is a bit more complicated than people initially think. Some of the most helpful resources in researching this topic were:
Lastly, I did not review validating, resizing, and in general more sophisticated processing of file uploads. These would all need thorough evaluation prior to real production work loads. In particular I would love to dive further into Notion and simliar productionized upload processes to see what can be gleaned from their APIs.